


Automation is getting more and more required in organizations today simply because it saves QA engineers a lot of time to do regressions and allows fast feedback about the quality of the code and the product. Almost every company today has some form of software automation. Whether it is on the API or UI level, automation testing is getting more and more popular and automation engineers are in high demand.
In this blog post, we will focus on UI automation in the Selenium framework. The core of UI automation is the way how we are locating elements. We will get in detail on how to locate elements, what is the preferred way and of course, there’s no better explanation than some basic examples.
What is WebElement?
Everything that is included in the HTML is basically a web element. We can locate links, buttons, checkboxes, images, titles, paragraphs, heading, footer, panels, etc. Selenium wraps those elements as objects of the web element and as a result, we have a DOM structure where all the elements are nodes in the DOM itself. The DOM is getting created immediately by the browser when the webpage is started. So we have the ability to do manipulation with the elements.
For example, if we want to locate some elements and get their locator value we can use the FindElement or FindElements commands.
How to locate elements?
FindElement
It is used to locate (identify) a single web element on the web page. Inside the command, we pass the type of the element locator and as a result, we are expecting the web element as a return value. If the element is not found, this command usually returns an exception of type NoSuchElementException.
Let’s take a C# Selenium example even though the concept is the same using other languages but the namings and syntax are different.
protected static IWebElement element;
element.FindElement(By.{{PROVIDE_TYPE_OF_LOCATOR}});
IWebElement is an interface that defines all the actions and controls the user would do on a webpage. Some of them are clicks, input text submits, get values, get properties, etc. In this case, we create a field called an element of type IWebElement, and then we can access the FindElement method wherein the brackets we must enter the type of locator we want to locate the element by using the By unique keyword.
FindElements
It is used to identify multiple elements and returns a list of elements. If there is no matching element with that locator, FindElements will return an empty list.
element.FindElements(By.{{PROVIDE_TYPE_OF_LOCATOR}});
Instead of returning a single WebElement, this methods returns a collection of web elements:
ReadOnlyCollection<WebElement>
We will use both methods to locate element/s by different types of locators.
Types of element locators
Now that you have a basic understanding of the core commands of element selection, it’s time to list the types of locators which are generally used. We will use www.qamind.com for identifying elements.
ClassName
This method locates the element by its class name. This locator is usually useful for locating multiple elements since many elements in an HTML page would have the same class name. So using this locator to fetch all of them in a list would be a good approach.
Example:
ReadOnlyCollection<IWebElement> elements = element.FindElements(By.ClassName("qamind_class_1"));This will returns a list of all the elements that have the class name “qamind_class_1”. Then we can loop through them for fetching their values or we can use the index value to get a specific element that we want to fetch.
Id
Every element in the DOM must have an ID. That is one unique identifier per element. In an ideal world, every application’s element should include an ID attribute but that’s not always the case. This approach where we locate elements by ID is the most common way and it should be used whenever there’s an ID. It is also the fastest way during test execution.
Example:
<div id="qamind_id_1">Title</div>
element.FindElement(By.Id("qamind_id_1"));
If available, always try to use ID’s to locate elements.
LinkText & PartialLinkText
These two methods locate elements by their link tag (“a”). The first one matches if the link text is exact and the second one matches if the link contains the partial text. For example, if we have something like this:
<a href="https://www.qamind.com">QAMIND Website</a>
Locate element by link text would look like:
element.FindElement(By.LinkText("QAMIND Website"));
And by partial link text:
element.FindElement(By.PartialLinkText("QAMIND W"));
Name & TagName
There can be elements where the name attribute is present. If yes, then we can select that element by its name value since there is a low chance that that would change often in the future.
Example:
<div name="About Me Page">About Me</div>
element.FindElement(By.Name("About Me Page"));
Selecting the element by tag name should be used as a last resort or should be avoided. This method selects the element by its HTML tag name. This approach of locating elements can be used if the elements cannot be detected by one of the already mentioned types of locators or the ones that will be mentioned later.
<li>About Me</li>
element.FindElement(By.TagName("li"));
As you can see there is a list tag which we are identifying the element. But one website can contain N number of <li> tags so locating a specific element can be tricky. Also, it’s not a good practice to be followed especially with the fact that you can already identify it by something else which is more useful, faster, and not that prone to changes.
CssSelector
In modern web application development where most of the organization follows the latest trends around which development framework is the best and so on, often you will find yourself in a situation where elements don’t have ID’s, their class names are automatically generated and they end up having the same class name values, rarely you can find name attributes end so on.
That’s why we have CSS selectors. This approach can be very intuitive especially when you get used to it. It can be a bit tricky at a first point but after you figure out how you can easily locate one element, the rest of them are pretty easy to identify.
Let’s try to locate the Recent Posts title in the left widget on the QAMIND’s home page.
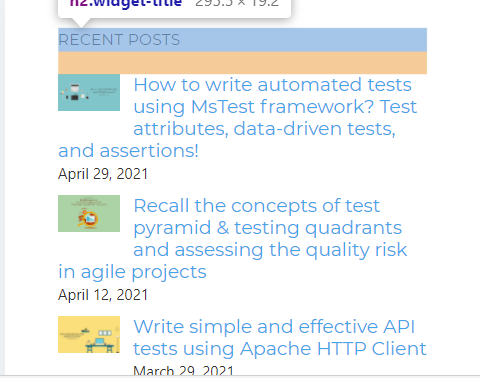
The title has these attributes in the HTML:
<h2 class="widget-title">Recent posts</h2>
We have 3 options here. Locate the element by:
- tag name
- class name
- css selector
If we locate the element by tag name we will end up with 17 elements found
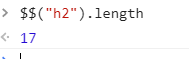
So., in order to find that specific element we need to specify the index (the number of the element’s position in HTML). In this case:
$$("h2")[6]
But this is not a good practice since the HTML structure can be prone to change especially when adding or removing h2 tags.
If we select the element by class name we would end up having 6 elements overall:
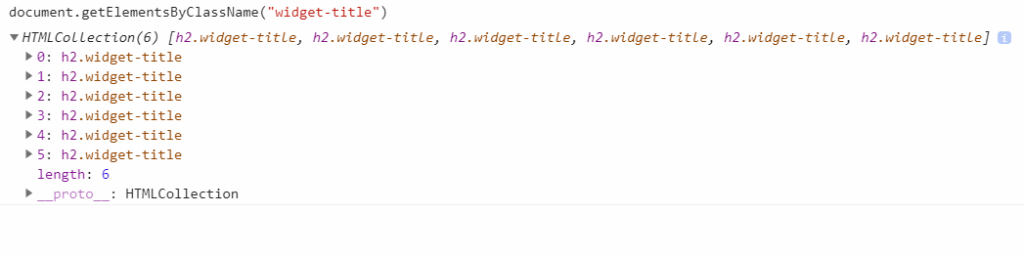
The goal is to find that specific element but not using indexes. Pay close attention to the selected HTML section:

With CSS locators we can locate elements only forward down the DOM tree. That means that we can try and use the parent element that can help us with the element identification.

We’re moving two rows above and entering the id of the whole widget. Then we hit SPACE and with “.” and then the name of the class we are selecting the CSS value of that class name. From the screenshot above you can see that we end up having only one element without using indexes. CSS selectors can be easy to learn, are faster during execution, and have more community support than XPath let’s say.
XPath
It can search for an element backward and forward compared to CSS selectors. You can fetch which element you like no matter if that element does not have any other attributes to search for. It uses path expression for HTML and XML element locating. Finding elements by XPath generally works pretty good but on the other hand, this type of locator, search in the DOM tree to try to find the exact XPath that you’ve provided, hence, it becomes slower compared to the other selectors. Plus there’s a big chance that the element position will change (the HTML structure will change) and then your test will fail due to the element not found exception. This locator is prone to changes due to frequent development.
I personally, would rather use CSS over XPath but in projects where there are already settled testing strategies and where the HTML design is finalized, then XPath can be helpful.
Example:
<input type="submit" class="search-submit" value="Search"></input>
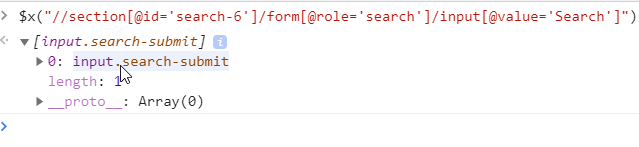
As you can see, we travel to the HTML tree section by section to eventually arrive at the element position. We can do this for every single element on the HTML page.
Interested to learn more about automating tests using Selenium? Enroll Now for Selenium Certification Training By Edureka and increase your chances to get hired by Top Tech Companies.
Conclusion
Now you have a more general knowledge of what are selectors, how to use them, and when it would be a good practice to include them in your test framework. Which one would you use depends on your project-based technologies and of course the automation testing strategy that is set. My preferred choice for locating elements would be Id, CSS, and Class Name.
Share This Post
Latest Posts
- Test Analyst’s Responsibilities in Risk-Based Testing
- Crucial Aspects Of Superior Test Code Quality
- Streamline Your Cucumber BDD Tests with Gherkin Lint: A Comprehensive Guide
- How to Test Authentication and Authorization with Confidence + Best Tips
- Exploring the Three Scrum Artifacts: Grasping Their Essence and Effective Utilization










One reply on “How to easily locate elements using Selenium?”
A very thorough and detailed explanation. Great read. Could be very helpful for less-experienced automation testers to grasp the basics and improve their skills.
Comments are closed.