


Intro
Choosing the right test framework for automating your web application is never an easy job. Many questions need to be answered like:
- What is the most beneficial we are going to get from that framework comparing to others?
- What are the disadvantages by using that framework?
- How complicated it is to implement?
- How hard it is to learn it and improve it as the development goes on?
Nevertheless, whatever you choose, make sure you have a proper strategy behind that decision and at least an initial knowledge of how everything is supposed to work once implemented.
When we discuss web UI automation, the first thing that comes up to my mind is whether the application under test is Angular, React, or Vue framework-based. If it’s Angular-based, then the choice is straightforward (at least for me). I would go with the Protractor framework that has many benefits in automating angular apps comparing to other automation frameworks. This can be coupled together with all of the BDD frameworks like Jasmine, Mocha, or Cucumber.
In any other case, a Selenium and Cucumber framework is what would I would choose.
In this blog post, I’m going to show you how you can create a simple but elegant Selenium & Cucumber framework for web UI automation.
Selenium and Cucumber framework folder structure
Tools & Technologies that I’m going to use to create this framework:
- IDE: Visual Studio Code
- Automation Framework: Selenium
- BDD Framework: Cucumber
- Language: Typescript
- Package manager: npm
Let’s try and automate a scenario from the www.qamind.com home page.
Root files
I would assume you’re familiar with installing Node and NPM and downloading chromedriver (since the test will be executed against the Chrome browser) and you know how to set a project to be typescript based (tsconfig.json).
The next step would be to install Selenium and Cucumber frameworks as well as things that are a must like:
- bunyan logger
- cucumber-console-formatter
- eslint
- gherkin-lint
- multiple-cucumber-html-reporter
- prettier
- chai
Once everything is installed your package.json file should have something like this:
"dependencies": {
"@cucumber/cucumber": "^7.3.1",
"@types/bunyan": "^1.8.7",
"@types/chai": "^4.2.21",
"@types/ini": "^1.3.30",
"@types/lodash": "^4.14.171",
"@types/mocha": "^9.0.0",
"@types/node": "^16.4.3",
"@types/selenium-webdriver": "^4.0.15",
"@typescript-eslint/eslint-plugin": "^4.28.5",
"@typescript-eslint/parser": "^4.28.5",
"bunyan": "^1.8.15",
"chai": "^4.3.4",
"chromedriver": "^92.0.0",
"cucumber-console-formatter": "^1.0.0",
"eslint": "^7.31.0",
"gherkin-lint": "^4.2.2",
"multiple-cucumber-html-reporter": "^1.18.0",
"prettier": "^2.3.2",
"selenium-webdriver": "^4.0.0-beta.4",
"ts-node": "^10.1.0",
"typescript": "^4.3.5"
}We need to configure cucumber since it is our main test execution driver. And that configuration is made in a file called cucumber.js:
export const cucumber-config= [
"--require ./src/steps/**/*.ts",
"--format json:test-report/result.json",
"--format cucumber-console-formatter",
"--require-module ts-node/register",
"--publish-quiet"
].join(" ");Here we specify, the path of the step definitions(main functions that connect the features + page objects), gathering the results in a .json file, formating the console log, registering the typescript compiler for all files, and disabling the below message at the end of each test execution set the publish-quiet parameter.
The final part the is of importance is the actual reporter that we will construct after each test execution. Since you’ve already installed multiple-cucumber-HTML-reporter you can create a separate .js file where you can configure the reporter to generate an HTML report with all of the executed tests right after the tests are finished executing.
const report = require("multiple-cucumber-html-reporter");
report.generate({
jsonDir: "./test-report/",
reportPath: "./test-report/",
displayDuration: true,
openReportInBrowser: true,
reportName: "QAMIND TESTS",
});The jsonDir is the path to which the JSON files are going to be stored, the reportPath is the place where the report will be created, displayDuration see to true will display the duration of each step, scenario, and feature, openReportInBrowser will open the report in the browser and the reportName is the name of the report that will be created.
Selenium-wrapper
This folder will contain all the selenium related methods for:
- Finding the element (fetch phase)
- Waiting the element (wait phase)
- Interaction with the element (interact phase)
Also, this folder will also contain the main browser-related methods like:
- Navigation
- Change window size
- Refresh page
- Go back
- Close browser
- Quit driver
- delete cache and cookies
First of all, let’s build the chrome driver
In a separate abstract class, we will build the driver and store the current state in a static property
const chrome = require("selenium-webdriver/chrome");
const chromedriver = require("chromedriver");
const webdriver = require("selenium-webdriver");
public static driver: WebDriver = Driver.buildDriver();
private static buildDriver() {
log.info("Starting chrome driver...");
chrome.setDefaultService(
new chrome.ServiceBuilder(chromedriver.path).build(),
);
return new webdriver.Builder()
.withCapabilities(webdriver.Capabilities.chrome())
.build();
}We start with some of the browser-related methods. In a separate class that extends the abstract class we can have some of the following static methods:
public static async closeBrowserAndDriver(): Promise<void> {
if (this.driver != null) {
await this.driver.close();
await this.driver.quit();
log.info("Browser and driver are closed!");
} else {
log.info("Browser and driver are already closed!");
}
}
public static async maximizeBrowserWindow(): Promise<void> {
await this.driver.manage().window().maximize();
log.info("Browser window maximized!");
}
public static async navigate(url: string): Promise<void> {
log.info(`Navigate to ${url} URL....`);
await this.driver.navigate().to(url);
}These would be some of them which we will be using quite often during our automation. Closing the browser, maximizing the browser window, and navigating to a specific URL passed as a string argument. All of them are static since their state would not be changed during execution and if you can notice I’m using the logger (initializing it by using: const log = Logger.createLogger({ name: “Browser Log” });) now since it would be much easier to debug if something went wrong during execution. Also, it shows us what is currently happening in the console log once the test is execution which is really nice.
Then we create three different classes:
- Class that handels the element fetching
- Class that handels the dinamyc element wait
- Class that handles the interaction with an element
In the element fetching phase we can have many elements finding methods (would not go into details explaining all of them) but what comes down to is the following:
public static async fetchElement(locator: Locator): Promise<WebElement> {
log.info("Fetching element...");
const fetchedElement = await this.driver.findElement(locator);
return fetchedElement;
}A static method that accepts a locator as an argument. Then by using the same property from the abstract class called driver, I find the element and I return a WebElement. This will be used anytime we need to locate a particular element from the page. There is also a method for fetching multiple elements by a locator and returns a list of web elements.
In the element wait phase, I will show one of the many methods with different purposes which can be really important and an integral part of every element manipulation cycle (fetch -> wait -> interact).
public static async waitForElementToBeDisplayedOnThePage(
element: WebElement,
): Promise<boolean> {
log.info("Waiting for element to become visible...");
await this.driver.wait(until.elementIsVisible(element), 5000);
if (element.isDisplayed()) {
log.info("Element is visible!");
return true;
} else {
log.error("Element is not visible!");
return false;
}
}As you can see there’s a dynamic wait provided by Selenium itself where I wait for that particular element to become visible on the page and if that element is not shown in 5 seconds, an error will be thrown. Then I check if the element is really displayed using an IF ELSE condition. If the element is there, I’m returning a boolean value of true, false if not.
With this, we can store the result of this method in a variable and assert it in the test before proceeding to the next step which adds another confirmation that that element is 100% there. There are many other dynamic waits by Selenium like wait until the element is loaded in the DOM, wait until the element disappears or wait until it becomes selected or clickable, etc.
Last but not least is the element interaction. Let’s say we want to click on an element.
public static async clickOnElement(element: WebElement): Promise<void> {
log.info("Clicking on the element...");
await element.click();
log.info("Element is clicked!");
}A web element as an argument when once provided, we’re just clicking on it and log that into the logger.
So what’s the purpose of separating all of these instead of putting these types of methods within the pages? We have a clear separation of page-related methods and Selenium-related methods. All the pages will use the methods from the selenium-wrapper folder. And if something changes, we’re going to do that in one place instead of many, achieving the method independence that we want.
Page-object
As you may already know, I follow the page-object model/pattern so in this example I’m going to create:
- Interface and implementation for a BasePage class, where all of the selenium-wrapper methods will be used
- Interface and implementation for a HomePage, all the methods related to the home page of www.qamind.com
- All the locators for all the pages
The BasePage interface will have a method like:
/**
* Waits for element to be enabled for clicking and clicks it
* @param locator The locator passed as an argument
*/
waitForElementToBeClickableAndClick(locator: Locator): Promise<void>;
And its implementation:
public async waitForElementToBeClickableAndClick(
locator: Locator,
): Promise<void> {
const element = await ElementFetch.fetchElement(locator);
await Browser.scrollToElement(
"arguments[0].scrollIntoView(true);",
element,
);
await ElementWait.waitForElementToBeClickable(element);
await ElementAction.clickOnElement(element);
}Noticed what I did there? So, I’ve practically used every selenium wrapper method with different outcomes in one single method. The waitForElementToBeClickableAndClick() method accepts a locator as an argument and then once received it will fetch -> wait -> interact with that element. We don’t ever need to worry about if we forgot to find the element, to click, or to put a wait in there. This method will do everything for us, we just need to pass the locator value and we’re done!
A similar approach will follow methods like, fetching the element text or input some text, refreshing the page to check the element label state, etc. The BasePage class will serve us as a connector between the pages and selenium.
Now, for the HomePage (which will extend the abstract BasePage class and will implement its interface) class, we will have, of course, an interface with all the methods that need implementation and the class itself. I’m going to show some of the methods that will be used to automate one scenario.
Let’s say we want to search for a particular blog by keyword.
public async searchForBlog(text: string): Promise<void> {
await this.clearInputFieldAndEnterText(
HomePageLocators.searchField,
text,
);
await this.waitForElementToBeClickableAndClick(
HomePageLocators.searchSubmit,
);
} public async verifySearchResult(): Promise<string> {
const searchResultText = await this.returnElementValueIfDisplayed(
HomePageLocators.searchResult,
);
return searchResultText;
}In the HomePage class, we create two methods, one for the actual searching and one for verifying that we found the correct blog. As you can see we use wrapped methods from the BasePage class which internally uses the already created selenium-wrapper methods. We’re just passing locators and reusing methods at this point. The second method returns the actual text from the search.
Step-definitions
Here all the mapping happens. First, importing the main Cucumber keywords:
import { Given, When, Then } from "@cucumber/cucumber";Then, the actual implementation steps:
When(
"Searching for blogs with search criteria: {string}",
async (criteria: string): Promise<void> => {
await homePage.searchForBlog(criteria);
},
);Then(
"The blog {string} appears",
async (expectedBlogTitle: string): Promise<void> => {
const searchResult = await homePage.verifySearchResult();
Assertions.checkIfActualEqualsExpected(
searchResult,
expectedBlogTitle,
`The search result: ${searchResult}`,
);
},
);The first step uses the searching for a blog method from the HomePage class and the second step verifies it by checking the actual vs expected outcome using Chai Library assertion. Btw, all the pages and the steps are asynchronous so they are actually waiting for the promise to be resolved before ending.
The {string} is the Cucumber expression were once presented, we must pass some argument in that method. And that argument is passed by not here, rather in the scenario within the feature file itself.
Features
Since we have everything in place now we’re finally in a position to automate the scenario we’ve been waiting to automate for our Selenium and Cucumber framework.
Background: QAMIND is open and cache and cookies are deleted
Given QAMIND is opened in Chrome
And Cache and cookies are removed and window is maximized
And Home Page is visible
Scenario: Verify that 'Using Protractor for smooth E2E automation' blog appears when searching for Protractor blogs
When Searching for blogs with search criteria: "Protractor"
Then The blog "Using Protractor for smooth E2E automation" appears
Every sentence that you see here is mapped with its actual implementation internally. The Background keyword serves as a before-step where something is being executed before each test (the multiple Given’s steps). In this case, QAMIND is opened, cache and cookies are deleted and the home page is visible. Those are going to be the three main before-steps that must be executed before each scenario so that we can have a clean picture of where we are before writing new scenarios.
This scenario searches for blogs that include the word Protractor and verifies that the first blog that appears is the blog with the title Using Protractor for smooth E2E automation.
Now, everything is ready and we can run the tests.
Run the test
To run the test I’m using a command called npx which is able to run every npm package from the npm registry even without being installed at all. In the package.json I created multiple scripts:
"scripts": {
"cucumber-js": "npx cucumber-js -b -p default",
"prettier": "npx prettier src/**/*.ts* --write",
"tests": "npm run prettier && npm run cucumber-js ./src/test-features/*.feature & node HTMLReporter.js"
}
The first one will trigger the cucumber runner, the second one will format the code. So in my case if I open the terminal and type:
npm run testsThis will format the code, and run every feature file in the relative path provided, plus will additionally trigger the HTML reporter to generate and open a report at the end of the test execution.
The final result:
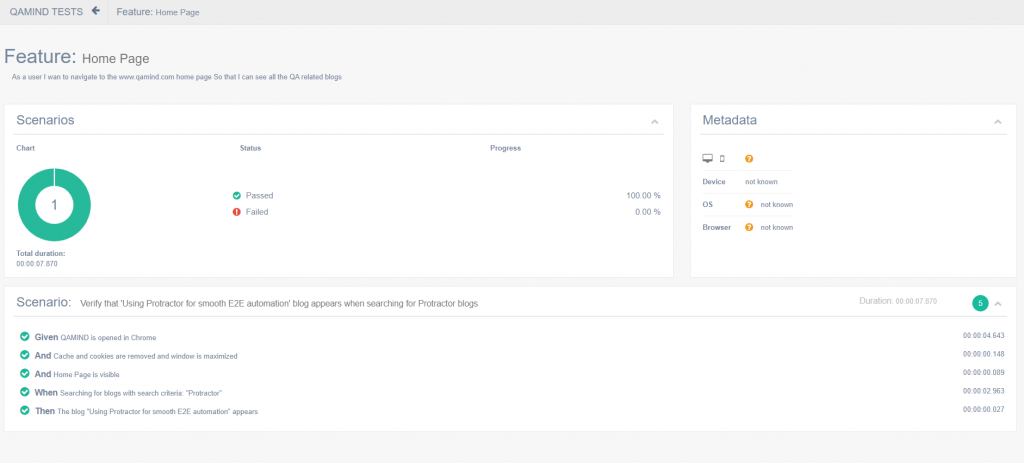
The report shows all the steps and features, their pass/fail status as well as their duration time.
Interested to learn more about automating tests using Selenium? Enroll Now for Selenium Certification Training By Edureka and increase your chances to get hired by Top Tech Companies.
I hope that by now, you have a general idea of how to create a simple but effective Selenium and Cucumber framework. Thank you!
Share This Post
Latest Posts
- Test Analyst’s Responsibilities in Risk-Based Testing
- Crucial Aspects Of Superior Test Code Quality
- Streamline Your Cucumber BDD Tests with Gherkin Lint: A Comprehensive Guide
- How to Test Authentication and Authorization with Confidence + Best Tips
- Exploring the Three Scrum Artifacts: Grasping Their Essence and Effective Utilization









